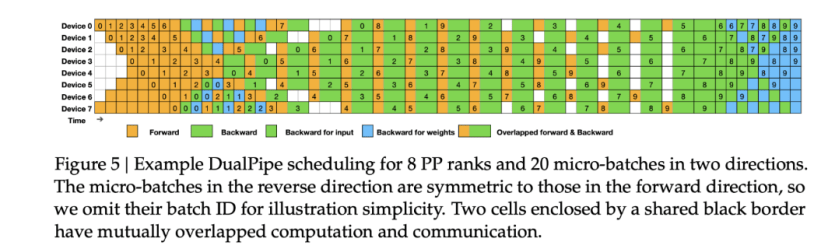
#DeepSeek AI has recently introduced DualPipe, a new way to train large AI models faster and more efficiently. Training LLMs is expensive and resource-heavy, and one major issue has always been idle time—when GPUs sit idle waiting for data to be processed.
Lets understand how Deepseek has tried to solve this problem:
🔹 Traditionally, AI training follows a step-by-step process—first, the model learns (forward pass), then it corrects mistakes (backward pass). This creates gaps where GPUs sit idle, wasting valuable computing power.
🔹 DualPipe changes this by making forward and backward passes run at the same time. Instead of waiting for one step to finish before starting the next, it overlaps both processes, reducing idle time and making training much faster.
If you want to understand this in a very simple way: Think of a restaurant kitchen. In a traditional setup, the chef first prepares all the ingredients, then starts cooking, and finally plates the dish. There are idle moments when one task finishes, and another begins.
DualPipe is like having multiple chefs working at the same time—one chopping vegetables, another cooking, and a third plating. This way, the kitchen runs smoothly without unnecessary downtime.
This will have a significant impact on training of LLM models:
🚀 Faster training: AI models can now be trained in less time, helping companies build better models, faster.
💰 Lower costs: More efficient GPU usage means less money spent on computing power.
🔧 Optimized hardware usage: Maximizes how GPUs process data, making large-scale AI training more practical.
Companies like OpenAI, Meta, and Google have worked on similar efficiency improvements, such as ZeRO (DeepSpeed) and Chimera (Li & Hoefler), but DeepSeek’s DualPipe appears to be one of the first to fully implement bidirectional parallel scheduling across micro-batches in large-scale training.
DualPipe is a big step toward making LLM training faster and more cost-effective. As models get larger, innovations like this will be critical for AI companies looking to stay competitive.
🚀 DeepSeek’s DualPipe: A new breakthrough in LLM training efficiency