For those following Retrieval Augmented Generation (RAG), it’s clear how RAG improved response relevance by addressing basic keyword and best-match limitations. RAG lets users tap into high-value IP/documents, significantly enriching LLM outputs. 📄💡
However, limitations persisted—about 6% of retrieval failures impacted consistency. Lowering this failure rate boosts reliability, and Contextual RAG is making that happen.
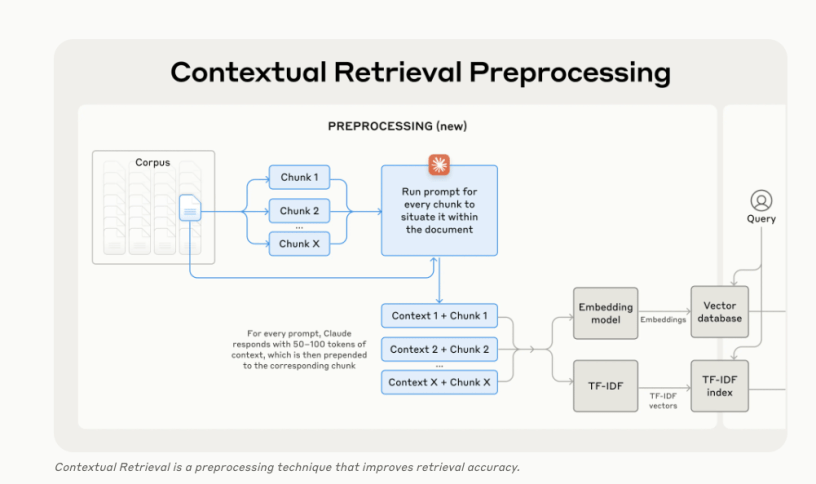
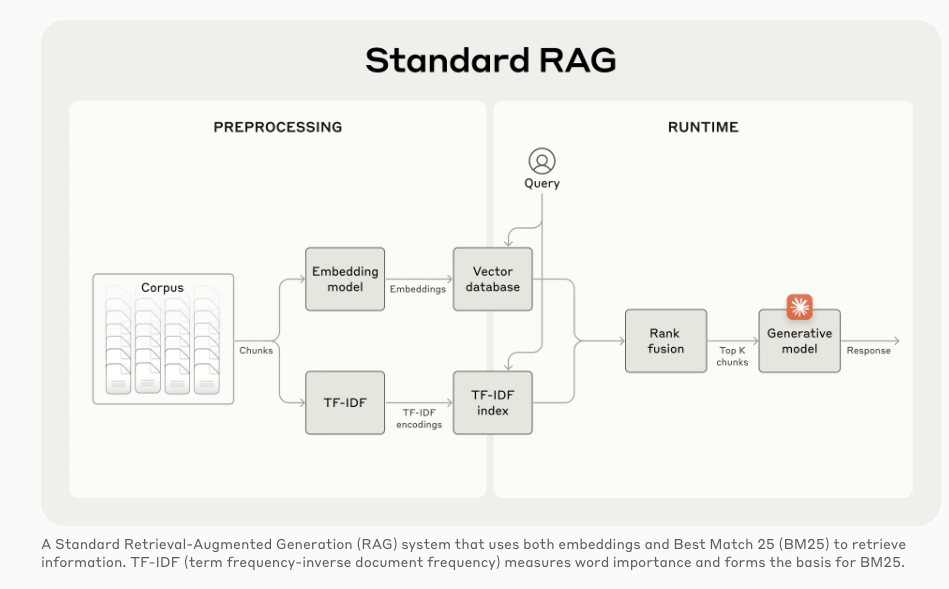
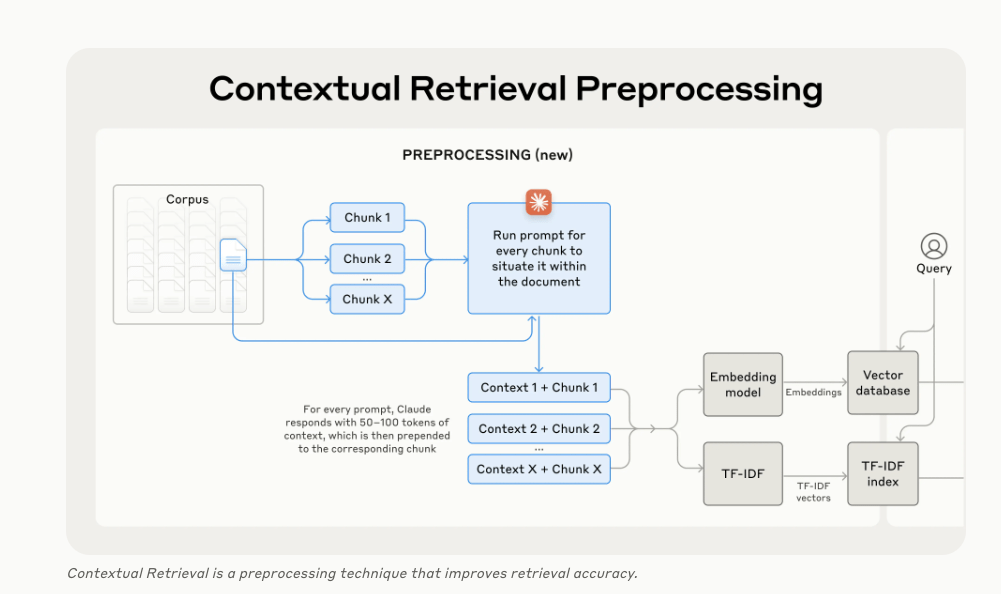
Contextual RAG maintains context across chunks (documents split into chunks), creating a more accurate retrieval system. Context RAG introduces a pre-processing step that combines context + chunk before embedding → vector storage → rank fusion, also enhancing BM25 searches!
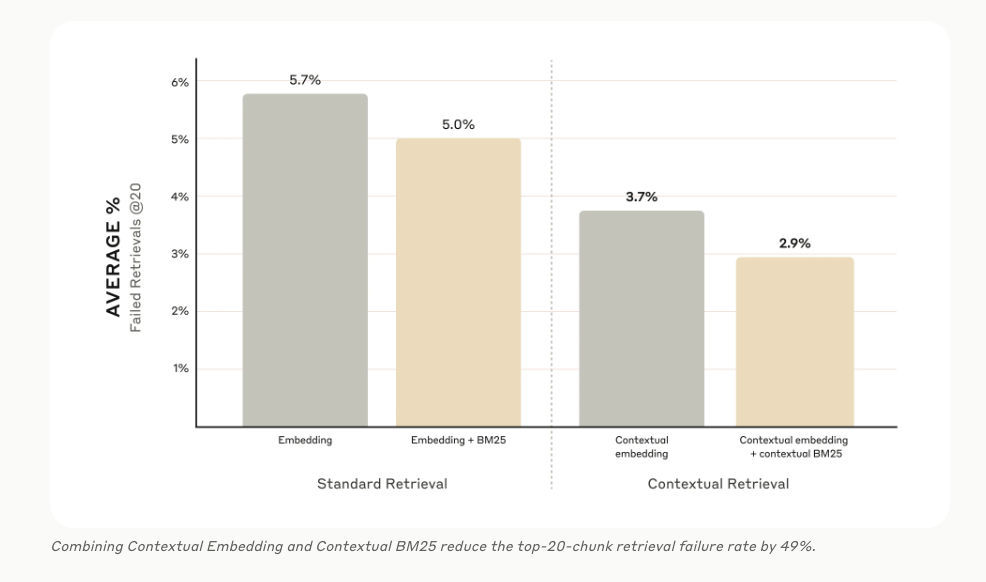
The initial performance metrics look positive:
✅ Contextual Embeddings reduced top-20-chunk retrieval failures by 35% (from 5.7% to 3.7%).
✅ Combining Contextual Embeddings and Contextual BM25 reduced these failures by 49% (from 5.7% to 2.9%).
This makes it especially powerful for complex, context-driven domains, such as:
🏥 Healthcare: Enhancing patient care through more consistent medical research retrieval.
💼 Finance: Accurate financial analysis by preserving context across investment reports.
⚖️ Legal: Assisting lawyers with precise legal document retrieval, improving consistency in complex cases.
📞 Customer Support: Providing agents with quick, relevant information to resolve customer issues accurately.
🎓 Education: Helping students and researchers by gathering cohesive information from extensive study materials.
𝐂𝐨𝐧𝐭𝐞𝐱𝐭𝐮𝐚𝐥 𝐑𝐀𝐆 𝐛𝐫𝐢𝐧𝐠𝐬 𝐮𝐬 𝐜𝐥𝐨𝐬𝐞𝐫 𝐭𝐨 𝐦𝐚𝐤𝐢𝐧𝐠 𝐋𝐋𝐌𝐬 𝐫𝐞𝐬𝐩𝐨𝐧𝐬𝐢𝐯𝐞 𝐚𝐧𝐝 𝐫𝐞𝐥𝐢𝐚𝐛𝐥𝐲 𝐚𝐜𝐜𝐮𝐫𝐚𝐭𝐞.
