A few weeks back, I was part of a group discussing AI bias and how the underlying data is crucial to understanding this bias. I had called out in that discussion that it is not “AI that is biased”, but it merely reflects that bias that we currently have in real life which is represented in the datasets that the models are trained on.
Introducing Synthetic data not only takes us away from the ground reality but also presents its own set of challenges.
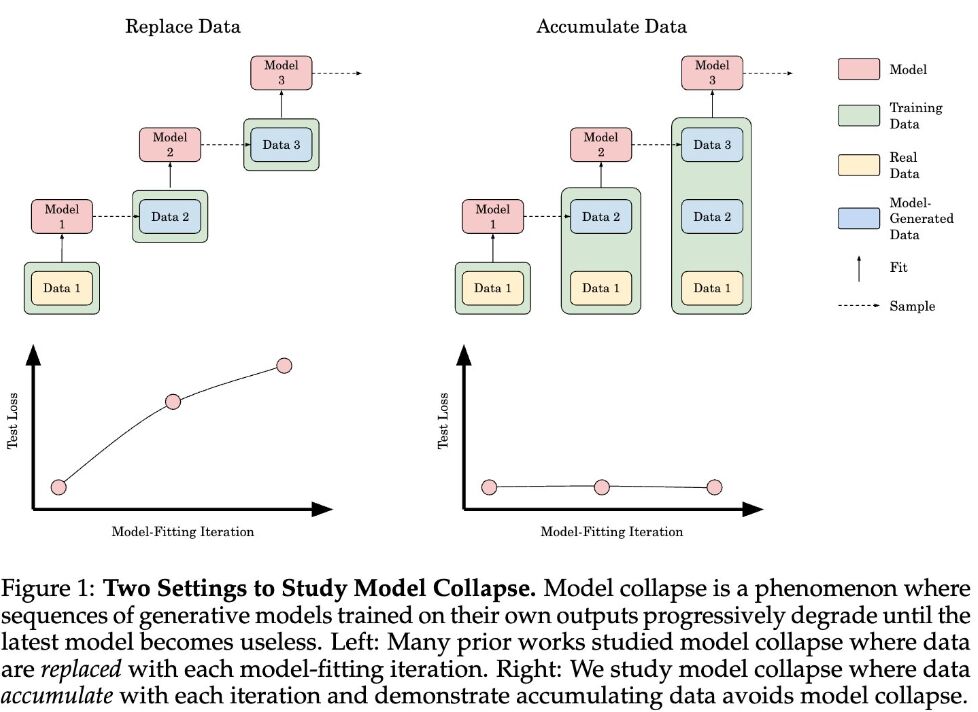
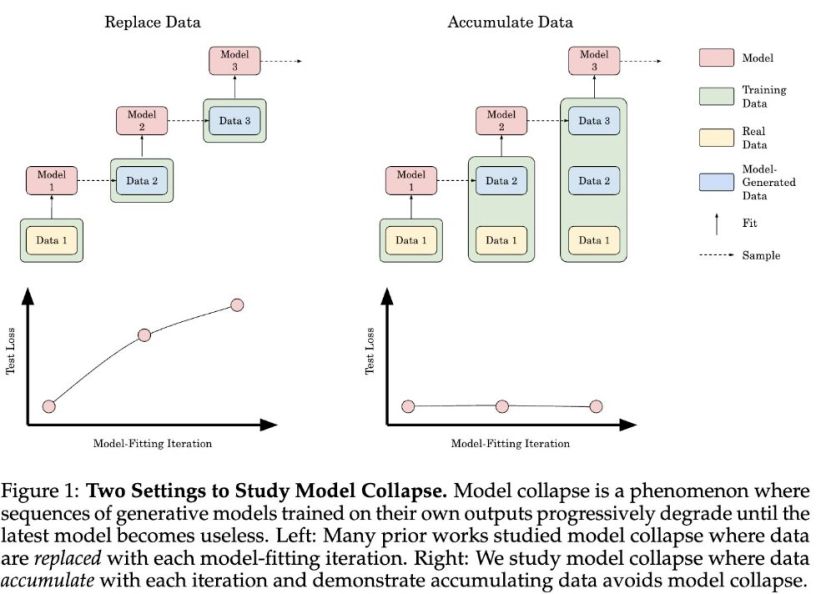
A recent paper from Meta AI and researchers from NYU and UCLA highlights a critical issue in AI development—the risks of training large language models using synthetic data.
While synthetic data helps scale training datasets, it doesn’t capture the richness and complexity of real-world data, leading to “model collapse.” 📉
🛑 Here’s the problem: models trained on synthetic data overfit on patterns that don’t fully represent real-world variability. As a result, they reinforce biases and errors, making them less reliable when applied to new, unseen data. Larger models are particularly affected, where even a tiny fraction (as little as 1%) of synthetic data significantly degrades performance.
The study shows that mixing real and synthetic data doesn’t prevent collapse. In fact, larger models amplify biases, leading to worse outcomes than smaller models.
⚠️ Key Takeaway: As we build more advanced AI systems, we must rethink how we use synthetic data in training. Current approaches aren’t enough. We need more advanced strategies to ensure that models trained on synthetic data can still generalize effectively to real-world scenarios.